![[Spring/Batch] Spring Batch Domain Language of Batch](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FvjS2A%2FbtsLIh2iUR8%2FAAAAAAAAAAAAAAAAAAAAAFtfO2csDudvXWztUmrc7l6B-55IDWveOsdn63BkSuMM%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DmToKETJFJMkH2o4bShoP13VNFgU%253D)


이번글은 Spring Batch에 관한 글이다.
SpringBatch는 Spring 생태계에 입문했다면 한번쯤 듣게되며 주로 대용량 처리에서 듣게 된다.
Spring Batch 5.x.x version으로 진행할 것이며 이번글은 이 SpringBatch 카테고리의 2번재인 핵심 객체 및 관계에 대한 정의를 다뤄보려고 한다. 기본적인 개념을 다루기 때문에 코드에 대한 깊은 설명을 진행하지 않는다.
공식 문서를 참고했다.
Configuring a Step :: Spring Batch
As discussed in the domain chapter, a Step is a domain object that encapsulates an independent, sequential phase of a batch job and contains all of the information necessary to define and control the actual batch processing. This is a necessarily vague des
docs.spring.io
1. 들어가며
요번 글에서는 Job, Step그리고 개발자 즉 내가 제공하는 ItemReader, ItemWriter같은 처리 단위가 포함된다.
이에 따라 Spring의 patterns, operations, templates, callbacks, and idioms에 따라서 다음과 같은 이점이 생긴다.
(자세한 용어는 차차 다루니 이런 점이 있다 정도만 이해하고 넘어가도 좋다.)
- 명확한 역할 분리로 인한 유지보수성 향상
Job, Step, ItemReader, ItemProcessor, ItemWriter같은 역할을 명확히 나눈다. - 아키텍처 계층 및 서비스 인터페이스 제공
각 기능을 인터페이스로 제공하고 기본구현 class를 제공한다. 필요에 따라서 이를 상속하거나 댈체할 수 있다. - 간단하고 기본적인 구현으로 빠르고 손쉽게 사용 가능
기본적으로 제공되는 Reader, Processor, Writer 덕분에 별도 구현 없이 빠르게 배치 작업 개발 가능하다. - 복잡한 요구사항에도 대응할수 있는 확장
Processor를 2개를 연결하거나 기본제공 class에 새로운 로직을 추가하는 등의 확장성이 좋다.
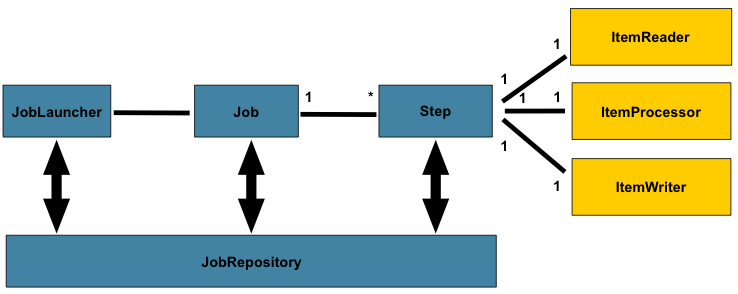
2. Job

Job이라는것은 spring-batch에서 작업 단위를 말한다. 가령 spring batch가 상하차 센터라면 job 1 상차, job 2 하차 같은 방식으로 나누는 단위이다.
XML또는 JAva기반으로 구성된다. 작업의 컨테이너 단위라고 생각하면 된다.
이 단위에서 중요한것은 3가지가있다.
- Job Name
- 정의 및 Step들
- Job 실패시 재시작 여부
JobInstance
Job의 논리적 실행 단위를 나타낸다. 동일한 Job이 실행되더라도 다른 parameter로 생성되면 다른 job, 같은 parameter로 생성되면 같은 job으로 판단한다. 아래예시를 한번보자 (다른점이 뭔지 비교만 해보자)
예시
// 첫 번째 실행: 파라미터 A
jobLauncher.run(job, new JobParametersBuilder().addString("key", "A").toJobParameters());
// 두 번째 실행: 파라미터 B
jobLauncher.run(job, new JobParametersBuilder().addString("key", "B").toJobParameters());
// 세 번째 실행: 파라미터 A
jobLauncher.run(job, new JobParametersBuilder().addString("key", "A").toJobParameters());- 첫 번째 실행
exampleJob + key=A
처음 실행함으로 새로운 JobInstance가 생성된다. - 두 번째 실행
exampleJob + key=B
파라미터가 다르기때문에 새로운 JobInstance가 생성된다. - 세 번째 실행
exampleJob + key=C
첫 번째 JobInstance랑 파라미터가 같기 때문에 같은 JobInstance가 생성되며 기존 생성된걸 재사용한다.
위와 같이 사용자는 Job Name과 Parameter를 통해서 Job을 식별하면 된다.
BATCH_JOB_INSTANCE 테이블
| JOB_INSTANCE_ID | JOB_NAME | JOB_KEY |
| 1 | exampleJob | key=A |
| 2 | exampleJob | key=B |
모든 Paramater가 JobInstance 고유 식별 key로 사용되지 않는다.
new JobParametersBuilder()
.addString("key", "A") // 식별에 사용됨
.addString("runtimeConfig", "config123", false) // 식별에 사용되지 않음
.toJobParameters();이런식으로 식별에 사용되지 않게 할수도 있다.
JobExecution
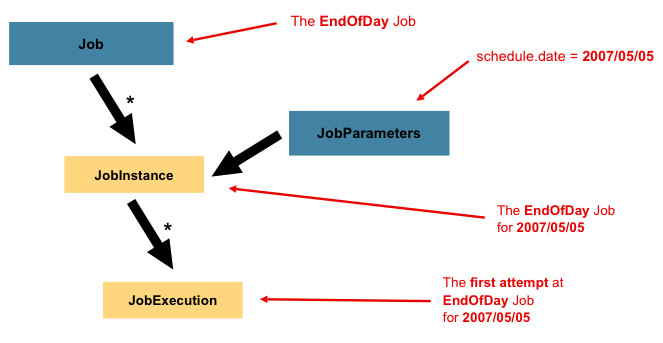
JobExecution은 JobInstance의 물리적 실행 정보를 나타내는 객체이다. 즉 하나의 JobInstance는 여러번 실행될 수 있드며 실행마다 별도의 JobExecution이 생성된다.
- 하나의 JobInsatcne는 여러번 실행될 수 있다.
- 각 실행은 새로운 JobExecution으로 기록된다.
중요한 속성
JobExecution 객체는 Spring Batch에서 자동으로 생성 및 관리된다.. 주요 속성은 다음과 같다.
| 속성 | 설명 |
| id | JobExecution의 고유 식별자 |
| jobInstance | 이 실행이 속한 JobInstance |
| status | 실행 상태 (STARTING, STARTED, COMPLETED, FAILED 등) |
| startTime | 실행 시작 시간 |
| endTime | 실행 종료 시간 |
| exitStatus | 실행 종료 상태 (성공/실패 여부 및 메시지) |
| failureExceptions | 실행 중 발생한 예외 목록 |
흐름
- 새로운 시작
Spring Batch가 JobLauncher를 통해서 실행되면 새로운 JobExecution이 생성된다. - JobExcution 상태 업데이트
실행 상태는 다음과 같음- STARTING :
JOB이 실행됨 - STARTED :
실제 작업이 진행 중 - COMPLETED
작업이 성공적으로 완료됨 - FAILED
작업 중 예외 발생으로 실패함
- STARTING :
- 메타데이터 기록
Spring Batch는 실행 중인 상태, 예외, 성공 여부를 자동으로 기록합니다.
BATCH_JOB_EXECUTION 테이블
| JOB_EXECUTION_ID | JOB_INSTANCE_ID | STATUS | START_TIME | END_TIME | EXIT_CODE |
| 1 | 1 | COMPLETED | 2025-01-09 10:00:00 | 2025-01-09 10:01:00 | COMPLETED |
| 2 | 2 | COMPLETED | 2025-01-09 10:02:00 | 2025-01-09 10:03:00 | COMPLETED |
| 3 | 1 | COMPLETED | 2025-01-09 10:04:00 | 2025-01-09 10:05:00 | COMPLETED |
3. Step

Step은 Spring Batch에서 Batch 작업의 독립적이고 순차적인 단위를 의미힌다.
즉 하나의 Job은 여러개의 step으로 구성될수 있다.
각 step은 특정 작업 (데이터 읽기, 처리, 쓰기)등을 수행하며 간단하거나 복잡한 작업을 처리한다.
StepExecution
특정 Step을 실행하는 동안 상태 및 통계를 추적하는 객체다. Step이 실행될 때마다 새롭게 생성되며, 실행 시점의 정보와 결과를 기록한다.
예시
Step 구성
- Step 1: CSV 읽기 (Read)
CSV 파일에서 데이터를 읽어 들이고 ItemReader로 전달
예: readCount는 1000으로 기록 - Step 2: 데이터 가공 (Process)
데이터를 가공하는 로직을 수행. 잘못된 데이터는 스킵(processSkipCount 증가)
예: 총 1000건 중 50건을 스킵해 처리된 데이터는 950건 - Step 3: 데이터 저장 (Write)
처리된 데이터를 데이터베이스에 저장. 저장 중 오류가 발생하면 writeSkipCount 증가
예: 데이터베이스 저장 과정에서 3건이 실패
단계별 StepExecution 속성
Step 1: Read
| Status | COMPLETED |
| readCount | 1000 |
| writeCount | 0 |
| readSkipCount | 0 |
| processSkipCount | 0 |
| writeSkipCount | 0 |
Step 2: Process
| Status | COMPLETED |
| readCount | 1000 |
| writeCount | 950 |
| readSkipCount | 0 |
| processSkipCount | 50 |
| writeSkipCount | 0 |
Step 3: Write
| Status | COMPLETED |
| readCount | 0 |
| writeCount | 947 |
| readSkipCount | 0 |
| processSkipCount | 0 |
| writeSkipCount | 3 |
통합 DB 저장 예시 (BATCH_STEP_EXECUTION 테이블)
| STEP_EXECUTION_ID | JOB_EXECUTION_ID | STEP_NAME | START_TIME | END_TIME | STATUS | READ_COUNT | WRITE_COUNT | READ_SKIP_COUNT | PROCESS_SKIP_COUNT | WRTIE_SKIP_COUNT | EXIT_CODE | EXIT_MESSAGE |
| 1 | 101 | readStep | 2025-01-13 12:00:00 | 2025-01-13 12:01:00 | COMPLETED | 1000 | 0 | 0 | 0 | 0 | SUCCESS | Read step executed successfully |
| 2 | 101 | processStep | 2025-01-13 12:01:01 | 2025-01-13 12:02:00 | COMPLETED | 1000 | 950 | 0 | 50 | 0 | SUCCESS | Process step executed successfully |
| 3 | 101 | writeStep | 2025-01-13 12:02:01 | 2025-01-13 12:03:00 | COMPLETED | 0 | 947 | 0 | 0 | 3 | SUCCESS | Write step executed successfully |
ExecutionContext
Spring Batch에서 Batch 작업 (Job or Step)의 상태를 유지하기 위해서 사용하는 Key-Value 기반 데이터 저장소이다. Batch 처리중에 데이터를 임시로 저장하거나, 실패 후 재시작할 때 상태를 복원하는 데 사용된다.
Repair Process
- 상태 저장 :
- ExcutionContext는 작업 실행 중의 상태 데이터를 Key-Value 쌍으로 저장
- 작업이 중단되기 전에 현재 진행 상태를 자동으로 또는 명시적으로 저장
- 중단 :
- 작업 중 예외 발생, 시스템 종료 등으로 Step이나 Job이 중단될 수 있음
- Spring Batch는 중단 시점의 ExecutionContext 데이터를 DB에 저장함
- 재시작 요청 :
- 사용자가 재시작 가능하도록 설정한 Job 또는 Step을 실행
- Spring Batch는 이전에 저장된 ExecutionContext 데이터를 복구
- 상태 복구 :
- 재시작 시 ExcutionContext 데이터를 역직렬화하여 복원
- 복구된 데이터를 기반으로 중단된 지점부터 작업을 이어서 실행
복구 관련 DB 저장 예시
Spring Batch는 ExecutionContext 데이터를 DB에 직렬화하여 저장한다.
BATCH_STEP_EXECUTION_CONTEXT 테이블 예시
| STEP_EXECUTION_ID | SHORT_CONTEXT | SERIALIZED_CONTEXT |
| 1 | {"currentLine": 450} | Serialized byte array |
| 2 | {"lastProcessedId": 800} | Serialized byte array |
복구 시 동작
- ExecutionContext를 역직렬화하여 메모리에 로드
- 필요한 상태(currentLine, lastProcessedId)를 애플리케이션 로직에서 참조
- 저장된 상태를 기반으로 작업을 이어서 진행
4. JobRepository & JobLuancher
JobRepository
Spring Batch의 영속성 계층으로 batch 실행 상태 및 메타데이터( BATCH_JOB_INSTANCE 같은 데이블에 저장되는 값)를 관리하는 핵심 역할을 한다. 이로인해서 실행 중 발생하는 상태를 저장하고 복구 가능하도록 만든다.
3가지 방법으로 설정을 할 수있다.
Spring Framework
DataSource 및 TransactionManager는 사용해서 DB를 연결하고 Transaction을 관리한다.
@Configuration
public class FrameworkConfig {
@Bean
public DataSource dataSource() {
return DataSourceBuilder.create()
.url("jdbc:h2:mem:testdb")
.username("sa")
.password("")
.driverClassName("org.h2.Driver")
.build();
}
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean
public JobRepository jobRepository(DataSource dataSource, PlatformTransactionManager transactionManager) throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setDatabaseType("H2");
return factory.getObject();
}
}SpringBoot
기본적으로 자동 설정을 지원하기 때문에 많은 설정이 간소화 된다.
application.properties 혹은 application.yml에 DB관련 설정만 추가하면 된다.
application.properties
spring.datasource.url=jdbc:h2:mem:testdb
spring.datasource.username=sa
spring.datasource.password=
spring.datasource.driver-class-name=org.h2.Driver
spring.batch.initialize-schema=alwaysJava Config
@Configuration
@EnableBatchProcessing
public class SpringBootConfig {
@Autowired
private DataSource dataSource;
@Autowired
private PlatformTransactionManager transactionManager;
@Bean
public JobRepository jobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setDatabaseType("H2");
return factory.getObject();
}
}XML 방식
필자가 비선호 하는 방식이긴 하나(에러를 상대적으로 늦게 알게 됨으로) 설정을 xml로 나누는걸 선호하는 분들을 위해서 만들었다.
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch="http://www.springframework.org/schema/batch"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- DataSource 설정 -->
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="org.h2.Driver"/>
<property name="url" value="jdbc:h2:mem:testdb"/>
<property name="username" value="sa"/>
<property name="password" value=""/>
</bean>
<!-- TransactionManager 설정 -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- JobRepository 설정 -->
<bean id="jobRepository" class="org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="transactionManager" ref="transactionManager"/>
<property name="databaseType" value="H2"/>
</bean>
</beans>JobLauncher
Spring Batch에서 Job을 실행하는 Interface이다. 그래서 Job과 JobParameters를 전달받아서 실행해야하며 실행 상태를 JobRepository에 저장하게 된다.
예시는 간단한 cronjob을 통해서 jobLauncher를 돌리는걸 같이 보여주겠다.
cron 표현식에 따라서 Job이 주기적으로 실행된다.
Spring Framework 방식
JobLauncher
@Configuration
@EnableScheduling // CronJob을 위한 스케줄링 활성화
public class FrameworkCronJobConfig {
@Bean
public JobLauncher jobLauncher(JobRepository jobRepository) throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository);
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
}CronJob
@Component
public class FrameworkCronJobScheduler {
private final JobLauncher jobLauncher;
private final Job sampleJob;
public FrameworkCronJobScheduler(JobLauncher jobLauncher, Job sampleJob) {
this.jobLauncher = jobLauncher;
this.sampleJob = sampleJob;
}
@Scheduled(cron = "0 0/5 * * * ?") // 5분마다 실행
public void runJob() {
try {
JobParameters params = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(sampleJob, params);
System.out.println("Job executed successfully.");
} catch (Exception e) {
e.printStackTrace();
}
}
}Spring Boot 방식
application.properties
spring.datasource.url=jdbc:h2:mem:testdb
spring.batch.initialize-schema=alwaysspring boot는 자동으로 JobLauncher를 실행하기 때문에 Bean 정의가 필요 없다.
cronJob
@Component
public class BootCronJobScheduler {
private final JobLauncher jobLauncher;
private final Job sampleJob;
public BootCronJobScheduler(JobLauncher jobLauncher, Job sampleJob) {
this.jobLauncher = jobLauncher;
this.sampleJob = sampleJob;
}
@Scheduled(cron = "0 0/10 * * * ?") // 10분마다 실행
public void runJob() {
try {
JobParameters params = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(sampleJob, params);
System.out.println("Job executed successfully.");
} catch (Exception e) {
e.printStackTrace();
}
}
}5. Items
ItemReader
Step에서 읽기 단계를 당담하는 인터페이스이다. 데이터를 외부 소스(File, DB, API)등에서 읽어와서 Chunk 기반 처리의 첫 번째 단계를 수행한다.
기본적으로 제공되는 ItemReader들은 다음과 같다. 이들을 상속받거나 확장해서 마음대로 Custom할 수 있다.
- FlatFileItemReader : CSV, TXT 파일을 읽음
- MultiResourceItemReader : 여러 파일을 순차적으로 읽음
- JdbcCursorItemReader : DB에서 데이터를 커버 방식으로 읽음
- JpaPagingItemReader : JPA로 데이터를 페이징 해서 읽음
ItemProcessor
Step의 중간 단계로 Reader가 가져온 데이터를 처리 및 가공하는 역할을 한다.
- 사용자 정의 class : 데이터 필터링, 변환, 계산 등을 처리함
- lamda 혹은 method 참조 : 간단한 가공 로직에 사용함
- CompositeItemProcessor : 여러 processor를 chain으로 연결함
ItemWriter
데이터를 최종적으로 저장하는 역할을 한다.
File, DB, Message Queue등 다양한 대상에 저장이 가능하다.
- FlatFileItemWriter : CSV, TXT 파일로 출력
- JdbcBatchItemWriter : 데이터를 DB에 일괄 저장
- JpaItemWriter : Jpa로 데이터를 저장
- KafkaItemWriter : kafka에 메시지를 전송
이제 당신은 기본적인 Batch 이해를 완료했다!