![[DB/Oracle] INDEX [4]](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fu7QJm%2FbtsLbU1m12K%2F4MvTK32LwJrHajAtBnokk1%2Fimg.webp)


Oralce은 많은 기업이랑 개발자가 사용하는 강력한 관계형 데이터베이스 관리 시스템이다.
하지만 유로 버전이기 때문에 직장을 다니지 않는다면 접하지 않는 경우가 많고 입사 후에 처음 접하는 일이 많다.
처음 접하는 사람도 따라가기 쉽게 글을 작성해 보려고 한다.
요번 글에서 진행할 내용은 INDEX이다.
예제를 ORACLE로 다룰뿐 다른 DB에도 연관되는 것이 많다는 점이다.
1. INDEX?
INDEX라는 것은 테이블의 데이터를 빠르게 조회하기 위한 구조이다.
즉 SELECT를 사용해서 데이터를 조회할때 이를 효율적으로 진행하기 위함을 궁극적인 목표로 잡는다.
기본적으로 아래 정의를 알아야 한다.
이는 실행 계획을 실행하면 볼수 있기도 하다. 괄호 안에 숫자는 실행 속도이다. 낮은 숫자일수록 빠르다.(물론 상황에 따라서 속도는 다를수 있음에 유의하자)
- FULL TABLE SCAN (6)
정의 : 데이터베이스가 모든 테이블의 행을 처음부터 끝까지 읽는 방식이다.
특징 : 인덱스를 사용하지 않을경우 일어나는 일이며 데이터 양이 많을수록 성능이 저하된다. - INDEX SCAN (3)
정의 : 인덱스의 모든 항목을 읽는다.
특징 : 필요한 데이터가 인덱스에 모두 포함된 경우 일어난다. - INDEX RANGE SCAN (2)
정의 : 조건에 맞는 일부 인덱스 값만 스캔한다.
특징 : 범위 조건등이 사용되거나 인덱스가 걸린 컬럼에 조건이 있을때 일어난다. - INDEX UNIQUE SACN (1)
정의 : 단일 레코드를 읽는다.
특징 : 유니크 인덱스나 PK를 기반으로 찾을 때 일어난다. - INDEX SKIP SCAN (4)
정의 : 복합 인덱스에서 선두 컬럼을 사용하지 않고 뒤쪽 컬럼으로 검색한다.
특징 : 복합 인덱스가 있지만 조건이 뒤쪽 컬럼에만 걸릴 때 일어난다.
예시 : X,Y,Z 순서로 복합 키가 지정되어있을 때 Y,Z로만 검색을 할시 일어난다.
이때 INDEX SKIP SCAN으로 일어날지 FULL TABLE SCAN으로 일어날지는 옵티마이저가 결정한다.
(옵티마이저는 이번글에서 다루지 않는다) - TABLE ACCESS BY INDEX ROWID (5)
정의 : 인덱스를 통해서 ROWID를 찾고 그 ROWID로 테이블에 접근해서 데이터를 가져온다.
특징 : 인덱싱을찾고 한번더 테이블에 접근하게 된다. 인덱스에 필요한 모든 컬럼이 들어 있지 않으면 일어난다.
이를 확인하는 법도 알아보자
간단한 예시 테이블을 만들어보자 그리고 인덱싱을 적용해보자
-- EMPLOYEES 테이블 생성
CREATE TABLE EMPLOYEES (
ID NUMBER PRIMARY KEY,
NAME VARCHAR2(50),
AGE NUMBER,
CITY VARCHAR2(50)
);
-- 데이터 삽입
INSERT INTO EMPLOYEES VALUES (1, 'Alice', 25, 'Seoul');
INSERT INTO EMPLOYEES VALUES (2, 'Bob', 30, 'Busan');
INSERT INTO EMPLOYEES VALUES (3, 'Charlie', 35, 'Incheon');
INSERT INTO EMPLOYEES VALUES (4, 'David', 40, 'Daegu');
INSERT INTO EMPLOYEES VALUES (5, 'Eve', 45, 'Daejeon');
COMMIT;
-- AGE 컬럼에 인덱스 생성
CREATE INDEX IDX_EMP_AGE ON EMPLOYEES (AGE);실행 계획을 확인해서 콘솔창에서 보자
EXPLAIN PLAN FOR
SELECT ID, NAME, AGE
FROM EMPLOYEES
WHERE AGE BETWEEN 30 AND 40;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);위코드를 실행하면 아래 코드처럼 정보가 나온다

여기서 중요하게 봐야하는건 Operation이다. index를 잘 타고 있는지 확인하는 것이다.
2. 인덱스 종류 및 생성 방법
그럼 인덱스는 어떤식으로 만들까?
기본 방식
CREATE INDEX 인덱스명 ON 테이블명(컬럼명);
CREATE INDEX idx_employees_age ON EMPLOYEES(AGE);
pimary랑 unique로도 인덱스를 생성할 수 있다. (unique랑 primary를 사용시 바로 생성됨)
| NULL 허용 여부 | NULL 값을 허용하지 않음 | NULL 값을 허용 |
| 자동 인덱스 | 자동으로 UNIQUE 인덱스 생성 | 자동으로 UNIQUE 인덱스 생성 |
| 테이블 당 개수 | 테이블당 한 개만 선언 가능 | 여러 개 선언 가능 |
복합 인덱스
CREATE INDEX idx_employees_age ON EMPLOYEES(AGE);
CREATE INDEX idx_employees_name_age ON EMPLOYEES(NAME, AGE);컬럼의 순서가 중요하다. 예를들어서 AGE로만 조회하면 INDEX를 안탈수도 있다.
X,Y,Z 순서대로 인덱싱을 했다고할때
X,Y | X,Z | X,Y,Z | X 이런 4가지 방식은 인덱스를 타지만
Y,Z | Z | Y 이런식으로 인덱스를 타려고 시도하면 옵티마이저에 따라 다를수도 있지만 FULL SCAN이 될 확률이 높다.
함수 기반 인덱스
CREATE INDEX 인덱스명 ON 테이블명(함수(컬럼명));
CREATE INDEX idx_employees_upper_name ON EMPLOYEES(UPPER(NAME));예시로는 UPPER를 사용해서 대소문자 무시 검색이다.
2.1 B-Tree
기본적인 인덱스이다. Oralce에서 아무것도 설정하지 않으면 인덱스는 자동으로 B-Tree 인덱스가 된다.
- 구조 : 균형 트리 구조 (부모노드 왼쪽 자식노드는 부모보다 모두 작은 값, 오른쪽 자식노드는 부모보다 모두 큰 값)
- 동작 방식 : 루트 노드 -> 브랜치 노드 -> 리프 노드로 이어진다.
- 탐색 시간 : 모든 리프 노드의 높이를 동일하게 유지하기 때문에 탐색시간이 동일하게 유지된다. Olog(N) N=모든 노드의 수
- 특징 : 값이 정렬된 상태로 저장되며, 등가 검색, 범위검색 모두 효과적이다.

HOT SPOT 문제
순차적으로 값이 삽입될경우 특정 리프 노드에 데이터가 몰릴수가 있다. B-Tree구조에서 항상 오른쪽 리프 노드가 갱신될 수 있다. 이는 많은 세션이 같은 노드를 동시에 접근해서 경합이 발생할 수 있다.
이를 해결할수 있다. 데이터를 고르게 분산시켜야 한다.
- 역방향 인덱스
순차적으로 숫자를 넣긴하는데 이를 뒤집는다.
예시) 1001->1002->1003 순서대로 값이 생성된다면 이를 1001->2001->3001 이런식으로 저장하는 것이다. - 랜덤 키 값 사용
순차 키 대신에 UUID같은 랜덤한 값을 사용해서 분산을 유도한다. - 파티셔닝
데이터를 여러 파티션으로 나눠서 특정 노드에 부하가 집중되지 않도록 분산한다.
2.2 BitMap
아쉽게도 Enterprise 버전에서만 사용 가능하다.
CREATE BITMAP INDEX idx_employees_city_bitmap ON EMPLOYEES(CITY);BITMAP이라고 명시해줘야된다.
- 구조 : 각 고유한 값에 대해서 비트맵 (0 or 1) 을 생성한다. 각비트는 행번호를의미하며 값이 있으면 1 없으면 0으로 표현된다.
- 동작 과정 : 조건에 맞는 비트맵을 찾는다. 여러 조건이 결합되어 있으면 AND, OR 연산을 통해서 결과를 계산한다. 계산된 비트맵에서 1이 있는 위치를 찾아서 데이터 행을 반환한다.
- 탐색 시간 : O(N) N = 비트맵의 크기 비트 연산이라 빠르지만 데이터 양이 커지면 비트맵 크기가 커져서 성능이 저하된다.
- 특징 : 중복 값이 매우 많은 컬럼에서 적합하다. 읽기에 빠르지만 동시 쓰기 작업에는 비효율 적이다.
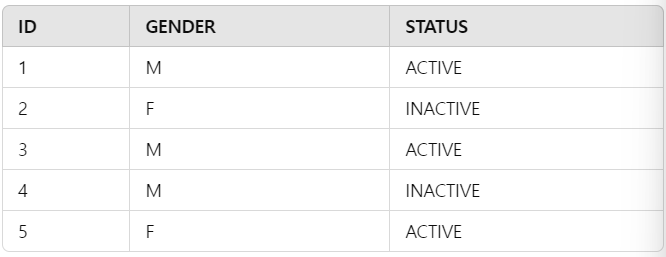
이렇게 값이 존재한다고 하자
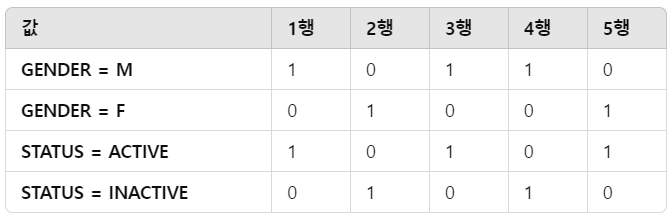
그럼 BITMAP에는 이렇게 작성된다. 1이면 값이 있는 것이고 0이면 값이 없는 것이다.
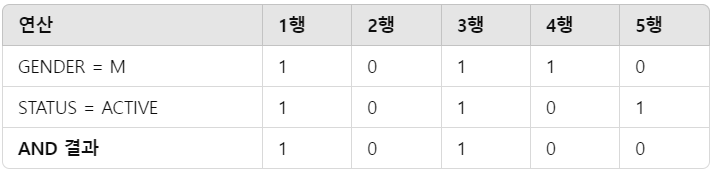
그럼 이런식으로 AND 조건을 넣어서 여성이고, STATUS=ACTIVE인 값을 빠르게 찾을 수 있을 것이다.
3. INDEX를 사용한 SQL 튜닝 전략
그럼 INDEX를 어떤 상황에서 사용해야 좋을까?
여기서 아래 3가지를 주의해야한다.
- 과도한 인덱스 생성 금지
인덱스가 많아지면 INSERT/UPDATE/DELETE 성능이 저하된다. - INDEX 통계 갱신
오래된 통계 정보는 옵티마이저가 잘못된 실행 계획을 선택하게 만든다. - 데이터 분포 확인
중복 값이 많은 컬럼은 비트맵 인덱스를 고려해야 한다.
3.1 WHERE
WHERE절에 인덱스가 생성된 컬럼을 사용해서 인덱스를 활용할 수 있다.
SELECT *
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 10;함수나 연산이 인덱스 컬럼에 적용되면 인덱스를 타지 못하니 유의하자 (ex: WHERE DEPARTMENT_ID +1 = 11;)
3.2 복합 인덱스 컬럼 순서 최적화
앞에서도 설명했지만 한번더 설명하겠다.
인덱스 예시: (DEPARTMENT_ID, SALARY)
SELECT * --좋은 예시
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 10 AND SALARY > 5000;
SELECT * --나쁜 예시
FROM EMPLOYEES
WHERE SALARY > 5000;복합 인덱스의 경우 왼쪽부터 순서대로 탐색한다. 따라서 선두 컬럼이 포함되어야 인덱스를 제대로 활용하는 것이다.
3.3 인덱스 컬럼에 대한 LIKE 사용
LIKE 검색에서 % 기호가 앞에 있으면 인덱스를 사용할 수 없다.
SELECT * --인덱스 적용됨
FROM EMPLOYEES
WHERE NAME LIKE 'J%';
SELECT * --인덱스 미활용
FROM EMPLOYEES
WHERE NAME LIKE '%OHN';%가 뒤에있을때만 적용 가능하다.
3.4 함수 기반 인덱스 활용
SELECT *
FROM EMPLOYEES
WHERE UPPER(NAME) = 'JOHN';기존 쿼리가 이렇게 되어있는데 함수기반 인덱스가 아니라면 아래같이 변환해주자
CREATE INDEX IDX_UPPER_NAME
ON EMPLOYEES (UPPER(NAME));3.5 불필요한 FULL TABLE SCAN 방지
FULL TABLE SCAN을 최대한 피하자
SELECT *
FROM EMPLOYEES
WHERE DEPARTMENT_ID IS NULL;NULL 값을 포함하는 경우에도 INDEX를 활용할 수 있도록 BITMAP INDEX를 생성하자. (B-Tree는 null 값을 제외하고 찾아준다. 즉 null값을 찾는다면 index를 타지 않고 찾는다.)
3.6 SELECT 절 최적화
불필요한 컬럼 조회를 줄여야 한다.
CREATE INDEX IDX_EMP_NAME_SALARY
ON EMPLOYEES (NAME, SALARY);
SELECT NAME, SALARY
FROM EMPLOYEES
WHERE NAME = 'JOHN';인덱싱을 하지 않은 컬럼을 조회할경우 조회가 한번 더 일어난다.
이를 위해서 커버링 인덱스를 사용하는게 좋다.
커버링 인덱스
예시 테이블
CREATE TABLE EMPLOYEES (
ID NUMBER PRIMARY KEY,
NAME VARCHAR2(50),
AGE NUMBER,
CITY VARCHAR2(50)
);일반적인 인덱스가 아래처럼 있다고 하자
CREATE INDEX idx_age ON EMPLOYEES(AGE);이때 아래코드처럼 조회하면 테이블 접근이 발생한다.
SELECT AGE, CITY
FROM EMPLOYEES
WHERE AGE = 30;커버링 인덱스는 city까지 인덱싱을해서 복합키를 만드는 것이다.
CREATE INDEX idx_age_city_covering ON EMPLOYEES(AGE, CITY);이러면 이제 인덱스만으로 결과를 반환한다.
3.7 JOIN & GROUP BY 시 INDEX 활용
JOIN에 사용되는 컬럼에 인덱스를 생성해서 성능을 개선한다.
4. 인덱스 모니터링 및 유지 관리
인덱스를 효율적으로 사용하려면 모니터링과 유지 관리가 필수이다.
인덱스 사용률 모니터링
SELECT INDEX_NAME, TABLE_NAME, LAST_USED
FROM DBA_INDEXES
WHERE TABLE_NAME = 'ORDERS'
AND LAST_USED IS NULL;LAST_USED : 인덱스가 마지막으로 사용된 시점이다. 만약 이것이 NULL 값이라면 사용된 적이 없는 것이다.
인덱스 조각화 확인 및 재구성
인덱스가 변경되다보면 조각이 생길수 있는데 이를 재구성할수 있다.
ALTER INDEX idx_orders_customer REBUILD ONLINE;ONLINE을 사용해서 서비스 중단 없이 정리할 수 있다.
'Database > Oracle' 카테고리의 다른 글
| [DB/Oracle] Optimizer [5] (0) | 2024.12.10 |
|---|---|
| [DB/Oracle] SQL & PL/SQL 기초 완벽 정리 (11g) [3] (0) | 2024.12.09 |
| [DB/Oracle] Oracle Architecture 이해하기 (11g) [2] (1) | 2024.12.09 |
| [DB/Oracle] Oracle 설치하기 (11g + Docker) [1] (0) | 2024.12.06 |
Coding, Software, Computer Science 내가 공부한 것들 잘 이해했는지, 설명할 수 있는지 적는 공간
![[DB/Oracle] Optimizer [5]](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FGskHg%2FbtsLcNHEtcr%2FaakcBBKYccz2ddnT2Hsm3k%2Fimg.png)
![[DB/Oracle] SQL & PL/SQL 기초 완벽 정리 (11g) [3]](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdlDdlq%2FbtsLaz4Rckk%2FBN8BGphfsFlY7U3272gSRk%2Fimg.png)
![[DB/Oracle] Oracle Architecture 이해하기 (11g) [2]](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdZ1Vib%2FbtsK9lrNrqi%2FOQlPzV60pPxyrKjhY14rc0%2Fimg.png)
![[DB/Oracle] Oracle 설치하기 (11g + Docker) [1]](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FHvBUw%2FbtsK9OGEJXy%2FBtlURZvakx98WxMsoBxoJ0%2Fimg.png)